

By 2026, approximately 70% of organizations have adopted Intelligent Document Processing as a central pillar of their automation strategy. However, most leaders still view these systems as simple tools for digitizing paper. Understanding how intelligent document processing works in the current landscape requires a shift in perspective from static data extraction to agentic intelligence. If your enterprise is still battling the high costs of manual data entry or the inaccuracies of legacy OCR, you're likely sitting on a mountain of unstructured data that remains untapped and underutilized.
You recognize that your back office needs more than just a faster way to read documents; it needs a system that can interpret intent and act on it. This guide will help you master the mechanics of agentic IDP and show you how to transform complex contracts and handwritten notes into strategic enterprise assets. We'll examine the technical stages of modern document processing, differentiate between basic extraction and autonomous agents, and provide a clear roadmap for enterprise-wide adoption that drives measurable financial returns.
Key Takeaways
• Identify the critical architectural differences between legacy OCR and modern IDP to ensure your data framework supports contextual understanding rather than just character recognition.
• Master the five core technical stages of how intelligent document processing works to streamline multimodal data capture and automated sorting across the enterprise.
• Discover how agentic AI layers transform static extraction into an autonomous workflow capable of reasoning about document content and cross-referencing external data sources.
• Establish a roadmap for scaling automation by transitioning from a Proof-of-Value to a full enterprise standard integrated with robust MLOps pipelines.
• Leverage flagship platforms like i_Nova to handle high-volume, complex unstructured formats and turn them into high-value strategic assets.
The Architecture of Intelligence: Defining IDP for the Modern Enterprise
Intelligent Document Processing (IDP) represents a fundamental shift in how serious enterprises handle information. It is a multi-layered AI framework designed to ingest, classify, and extract value from data at scale. While historical document processing relied on basic character recognition, modern IDP acts as the cognitive engine for your back office. It bridges the gap between human-readable paper and machine-ready insights. This framework integrates computer vision, natural language processing, and machine learning to achieve what was previously impossible for software alone.
To better understand this concept, watch this helpful video:
Understanding how intelligent document processing works requires categorizing the data it handles. Structured data is easy to manage. Semi-structured data, such as invoices, follows a loose pattern. The real challenge lies in unstructured data. This includes complex legal contracts, handwritten notes, and long-form emails. IDP provides the structural integrity needed to convert these chaotic formats into strategic assets. It doesn't just record text; it organizes it into a logical schema that your existing enterprise systems can actually use.
Why Traditional OCR is No Longer Sufficient
Legacy Optical Character Recognition (OCR) is essentially a pattern-matching tool. It looks for pixels that resemble letters. This approach works well for high-quality, perfectly aligned scans using rigid templates. However, modern business isn't rigid. When a vendor changes an invoice layout or a scan arrives skewed, legacy systems fail. They hit an "accuracy ceiling" that requires constant human intervention. Modern enterprises need semantic understanding. They need a system that knows what a "Total Amount Due" is, regardless of where it's placed on a page. This removes the burden of manual template creation and maintenance.
The 2026 Paradigm: From Document Processing to Document Intelligence
The arrival of Large Language Models (LLMs) and Generative AI has redefined the industry. We've moved past simple "reading" into the era of "interpreting." In 2026, document intelligence means the system understands business intent. It doesn't just see a date; it understands that date's relationship to a contract's expiration. This capability is a cornerstone of enterprise modernization. By shifting from reactive data entry to proactive intelligence, businesses free their teams for high-value creative work. This isn't just about efficiency. It's about building a resilient, future-proof operation that treats every document as a strategic data point.
The 5-Stage Mechanics: How Intelligent Document Processing Works
Modern enterprises don't just need data; they need precision. Understanding how intelligent document processing works involves a structured, five-stage lifecycle that transforms raw inputs into verified business intelligence. This sequence ensures that every piece of information, regardless of its source or format, is treated as a high-value asset. By breaking down the process into logical segments, businesses can identify bottlenecks and optimize for maximum performance.
Stage 1: Document Ingestion and Multimodal Data Capture.
The system aggregates data from diverse channels including email servers, cloud storage, and physical scanners.
Stage 2: Intelligent Classification and Sorting.
Using computer vision, the platform identifies the document type, such as a master service agreement or a tax form, without manual tagging.
Stage 3: Context-Aware Data Extraction.
NLP engines isolate specific data points by understanding their relationship to the surrounding text.
Stage 4: Automated Validation.
Extracted data is cross-referenced against existing ERP records or internal business rules to ensure consistency.
Stage 5: Seamless Integration.
The final, verified data is pushed directly into downstream workflows, triggering actions like payment processing or contract renewal.
Ingestion and Pre-processing: Preparing Data for Analysis
The first step in how intelligent document processing works is cleaning the signal. Raw inputs are often messy. Cloud-native ingestion pipelines apply sophisticated pre-processing techniques to ensure high accuracy. This includes deskewing tilted pages, noise reduction to remove digital artifacts, and binarization to sharpen text against its background. These steps allow the system to handle a high-volume stream of PDFs, handwritten forms, and low-resolution images with equal efficiency. For organizations looking to modernize their legacy stacks, our Agentic AI Engineering Services provide the technical foundation for these high-velocity pipelines.
Extraction and Validation: Ensuring Enterprise-Grade Accuracy
Once the data is clean, the focus shifts to semantic meaning. NLP engines go beyond simple text matching to identify complex entities, hierarchical relationships, and even the sentiment within a legal clause. This ensures the system understands not just the words, but the business intent. For high-stakes scenarios, a Human-in-the-Loop (HITL) model is deployed. This collaborative approach allows human experts to review edge cases, ensuring that the machine's speed is always tempered by human judgment. Confidence scores serve as the primary metric for automated versus manual routing, flagging any data point that falls below a pre-defined threshold for expert verification. This ensures that modern ICR can achieve up to 99.85% accuracy on handwritten notes, maintaining the integrity of your enterprise data.
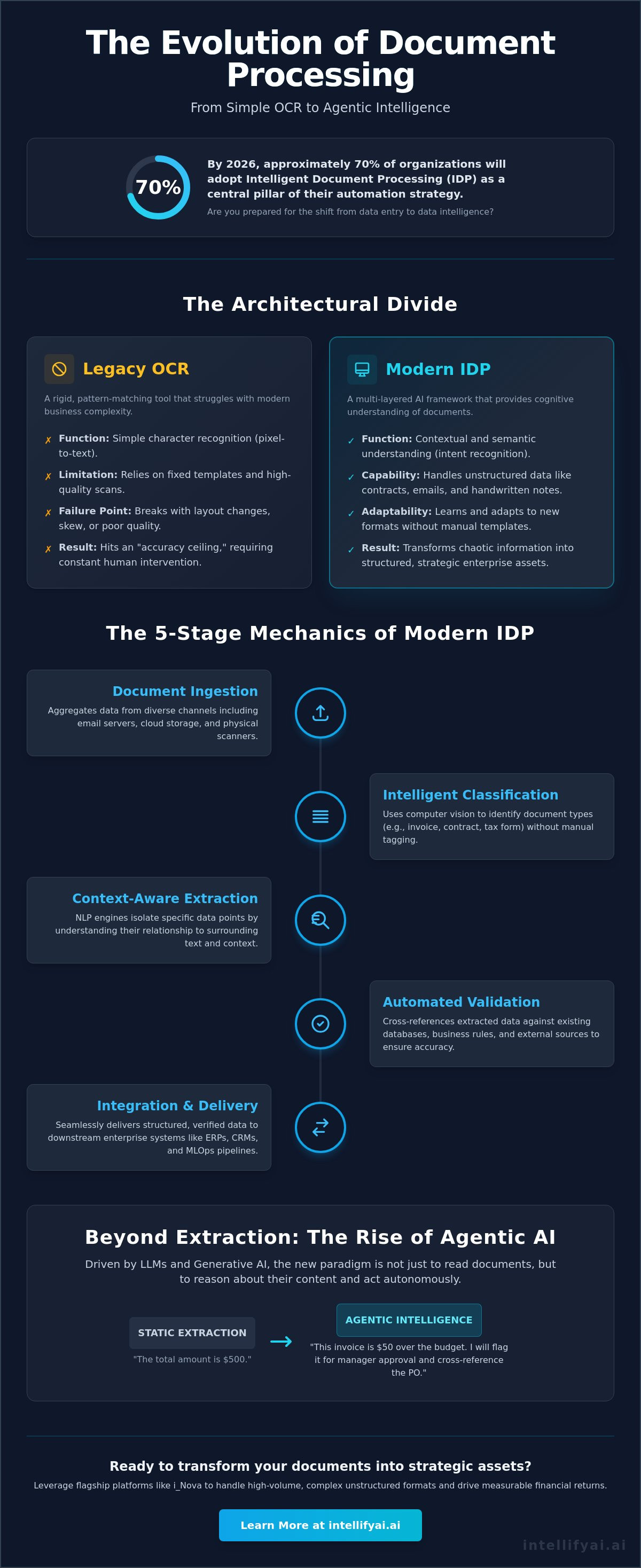
Beyond Extraction: The Role of Agentic AI in IDP Workflows
Most legacy solutions treat document processing as a linear, three-step pipeline: scan, extract, and export. This model is essentially reactive. To truly understand how intelligent document processing works in a modern enterprise, you must look at the agentic layer. Agentic AI serves as an autonomous reasoning engine that sits atop the data extraction phase. It doesn't just identify text; it understands the business context and the intent behind every document. This shift allows an AI agent to cross-reference extracted data with external databases or ERP systems in real time, ensuring that every data point is verified against a single source of truth.
The strategic impact is profound. We're moving from "extracting an invoice" to a complete lifecycle of "extracting, verifying, and paying an invoice" without human intervention. This doesn't mean AI is replacing your workforce. Instead, it's a liberating force. By removing the burden of repetitive data validation, you unlock human potential. Your team can pivot from manual entry to high-value creative work and strategic oversight. The technology acts as a partner, handling the high-velocity, low-complexity tasks that typically drain corporate resources.
Multimodal Processing: Understanding Text, Layout, and Logic
Modern IDP relies on Vision-Language Models (VLMs) to interpret documents the way a human does. It sees the spatial relationships on a page, recognizing that a signature's location or a table's structure carries as much meaning as the words themselves. The system understands the inherent logic of a form. For instance, it knows that the total must equal the sum of line items. Multimodal IDP is the seamless synthesis of vision and language that allows machines to perceive document logic rather than just character patterns. This capability is essential for processing complex, non-standardized contracts where layout varies significantly between vendors.
Autonomous Decision Making and Workflow Triggering
Once an agent understands the intent of a document, it can trigger specific business actions. If an insurance claim is processed and meets all pre-defined criteria, the agent can initiate an API call to the CRM to update the policyholder's status. Building these sophisticated triggers requires specialized Agentic AI engineering services to ensure deep integration with your existing tech stack. When the system encounters an exception, it doesn't just stop. It uses reasoning to determine if the discrepancy is a minor formatting error it can fix or a high-stakes anomaly that requires human review. This autonomous decision-making capability ensures that your back-office operations maintain momentum without sacrificing security or accuracy.
Strategic Implementation: Scaling IDP from PoV to Enterprise Standard
Scaling IDP across a serious enterprise requires more than a simple software installation. It demands a holistic strategy that treats technology as a central business pillar. You should begin with a Proof-of-Value (PoV). This phase allows your leadership to demonstrate accuracy and verify ROI before committing to a full-scale rollout. Once you validate the core logic, the system must move into a production environment that supports long-term viability. A successful implementation follows a clear progression:
Phase 1
Identify high-impact, high-volume document workflows for the initial PoV.
Phase 2
Establish success metrics focused on accuracy, reduction in manual touchpoints, and financial returns.
Phase 3
Transition to a centralized architecture that serves multiple departments.
Integration into existing MLOps pipelines is the next critical step. This provides the infrastructure for continuous monitoring and automated retraining. It's at this stage that your team truly masters how intelligent document processing works in a live, high-volume setting. By treating models as living assets, you ensure they adapt to changing document structures without manual intervention. Furthermore, Governance, Risk, and Compliance (GRC) must remain at the forefront. Establishing a "Center of Excellence" for document automation helps maintain these standards, creating a hub for knowledge and security across the firm.
Data Engineering: The Foundation of IDP Success
Successful IDP rests on the quality of your underlying data. Clean data pipelines are essential for training and fine-tuning models to the specific nuances of your industry. This is a foundational part of how intelligent document processing works, as the system's output is only as reliable as the data it consumes. Data labeling and the strategic use of synthetic data can accelerate model performance in niche areas where real-world examples are scarce. Version control for both data and models is a requirement. It guarantees that your results are reproducible and your system remains fully auditable for regulatory purposes.
The Strategic Architect Approach: Consulting for Long-Term Viability
Off-the-shelf retail software often falls short of complex enterprise needs. These generic tools lack the depth required for specialized industries and fail to integrate with bespoke legacy systems. A Strategic Architect approach favors custom AI strategy consulting to align technology with long-term growth. This ensures your roadmap accounts for future shifts in AI, maintaining your competitive edge. We focus on building a bridge between abstract technical fields and the practical needs of your growing company. To begin this transformation, contact our consulting team to design your implementation roadmap.
i_Nova: The Premier Intelligent Document Processing Platform
i_Nova is the definitive realization of advanced document intelligence. As IntellifyAi’s flagship platform, it is engineered specifically to meet the high-volume demands of modern enterprises. While previous sections detailed the theory of how intelligent document processing works, i_Nova provides the practical execution layer. It transforms raw, unstructured content into actionable intelligence with a level of precision that legacy systems cannot match. This platform serves as the critical bridge between static data and autonomous business execution.
Built on a cloud-native architecture, i_Nova integrates seamlessly with your existing MLOps infrastructure. This ensures that your document processing models are never stagnant. They evolve alongside your business, learning from every interaction and maintaining peak performance as document formats shift. This is not a temporary fix; it is a long-term investment in operational resilience.
Core Features of the i_Nova Platform
The platform distinguishes itself through multimodal extraction capabilities. It moves past the limitations of traditional OCR by synthesizing vision and language to understand complex layouts. This allows the system to process documents with the same nuance as a human expert, but at a vastly higher velocity.
Native Agentic Integration
i_Nova allows for end-to-end workflow automation, where the system reasons about content before triggering downstream actions in your ERP or CRM.
Enterprise-Grade Security
Compliance features are tailored for highly regulated sectors, ensuring data integrity and meeting strict GRC requirements.
Autonomous Exception Handling
The platform uses reasoning to resolve discrepancies, reducing the need for manual intervention in all but the most complex edge cases.
Transforming Your Back Office into a Strategic Asset
Adopting i_Nova signals a shift in operational philosophy. Your back office is no longer a cost-center burdened by manual data entry. It becomes a value-center focused on intelligence gathering. This transformation allows your workforce to step away from repetitive tasks and focus on high-value creative strategy. By automating the foundational mechanics of how intelligent document processing works, i_Nova empowers your team to act on insights rather than just managing files.
This approach positions your enterprise to handle growth without a linear increase in overhead. It creates a frictionless future where information flows directly into decision-making channels. To see this technology in action, we invite you to contact IntellifyAi for a custom i_Nova demonstration. Discover how a strategic approach to document intelligence can redefine your enterprise efficiency and unlock your team's true potential.
Secure Your Competitive Edge with Document Intelligence
Transitioning from legacy manual entry to agentic automation is a strategic necessity for the modern enterprise. You've seen that understanding how intelligent document processing works involves more than just software; it's about building a cognitive engine that executes business intent autonomously. By moving beyond simple extraction toward reasoning-based workflows, your organization can finally unlock human potential and focus on high-value strategy.
IntellifyAi stands as your global partner in this transformation. With a presence in the UK, USA, UAE, and India, we bring deep expertise in Agentic AI and enterprise-scale MLOps to your back office operations. Our flagship i_Nova platform is engineered to handle the most complex unstructured data while maintaining the security and performance your business demands. This is the bridge between raw content and a frictionless, automated future.
Don't let your unstructured data remain a stagnant liability. Schedule a strategic consultation to see how i_Nova can transform your document workflows. We're ready to help you modernize and scale with confidence.
Frequently Asked Questions
What is the difference between OCR and Intelligent Document Processing?
Intelligent Document Processing is the cognitive successor to traditional Optical Character Recognition. While OCR simply converts images into text characters, IDP uses natural language processing to understand context and meaning. It identifies relationships between data points, allowing the system to handle unstructured formats that static templates can't process. This evolution is central to how intelligent document processing works for enterprises looking to automate complex back-office workflows.
Can IDP handle handwritten documents and low-quality scans?
Modern platforms handle handwritten notes and degraded scans with high precision. Intelligent Character Recognition (ICR) achieves up to 99.85% accuracy on handwriting, while pre-processing techniques like binarization and noise reduction sharpen the signal from low-quality images. These capabilities ensure that your data engineering pipelines remain robust, even when dealing with non-standardized physical inputs from diverse global sources.
How does IDP improve data accuracy compared to manual entry?
IDP eliminates the fatigue-related errors inherent in manual data entry. By automating the extraction and validation stages, organizations often see a 70% to 90% reduction in document processing time. The system uses automated business rules to verify data against existing records. This ensures that only high-confidence data enters your ERP, significantly improving the overall integrity of your enterprise information assets.
What industries benefit most from Intelligent Document Processing?
Document-intensive sectors like finance, logistics, and healthcare derive the most value from IDP. Any industry dealing with high-volume unstructured data, such as complex contracts or medical records, can benefit from this technology. It allows these organizations to modernize their back-office operations and pivot their workforce toward creative strategy and high-value CX improvement frameworks rather than repetitive administrative tasks.
Is Intelligent Document Processing secure for sensitive financial data?
Enterprise IDP solutions prioritize security through robust encryption and clear audit trails. Platforms are designed to comply with rigorous regulations like HIPAA, ensuring that sensitive financial and personal data remains protected. By centralizing document processing within a secure, cloud-native environment, businesses reduce the risk of data leaks associated with manual handling and fragmented legacy systems.
How do I integrate an IDP platform with my existing ERP system?
Integration occurs through modern API layers and cloud-native ingestion pipelines. This allows the IDP platform to communicate directly with your existing ERP or CRM systems. To ensure long-term viability, these integrations should be managed within your broader MLOps framework. This setup enables the autonomous triggering of business actions based on the intent extracted from each document, creating a frictionless workflow.
What is the role of Generative AI in modern document processing?
Generative AI shifts the focus from simple extraction to sophisticated interpretation. Large Language Models allow systems to reason about a document's content and understand business intent. This technology enables the system to handle complex queries and summarize lengthy contracts effectively. It's a core component of how intelligent document processing works to transform raw content into a strategic enterprise asset.
How long does it take to implement an IDP solution at the enterprise level?
Implementation timelines vary based on the complexity of your document workflows and integration requirements. Serious enterprises should begin with a Proof-of-Value (PoV) to demonstrate accuracy and ROI within a few weeks. Scaling to a full enterprise standard typically follows a phased roadmap. This approach ensures the system is properly tuned to your specific data environment before becoming a central business pillar.






.svg)
