

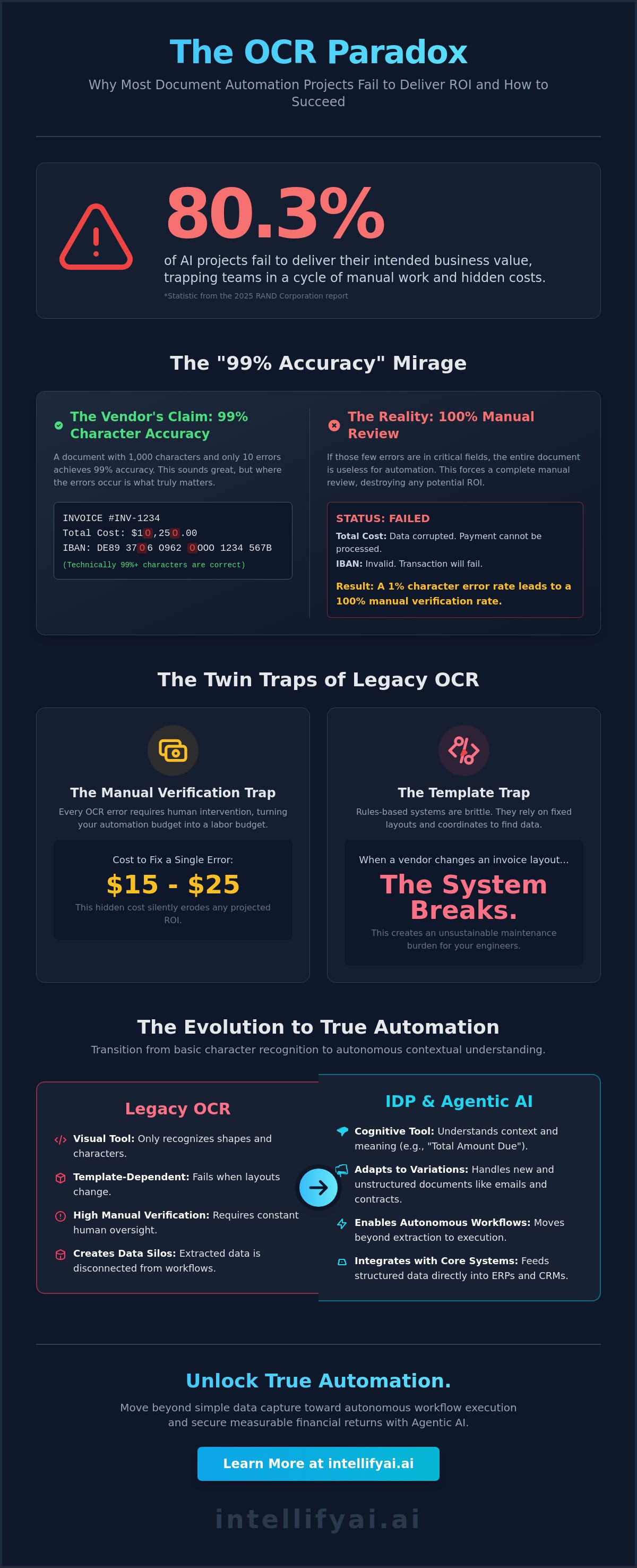
Did you know that 80.3% of AI projects fail to deliver their intended business value? This statistic from the 2025 RAND Corporation report highlights a painful reality for enterprise leaders who find themselves questioning why ocr projects fail to deliver roi despite massive initial investments. You were likely promised 99% accuracy and a total elimination of manual data entry. Instead, your team is likely trapped in a manual verification cycle, fixing errors that cost between $15 and $25 each while struggling with brittle templates that break the moment a vendor changes an invoice layout.
It's frustrating to watch your automation budget disappear into labor-heavy verification costs that never seem to decrease. We understand that true digital transformation isn't about character recognition; it's about contextual intelligence. This guide will show you how to move beyond legacy OCR and pivot toward Agentic AI and Intelligent Document Processing (IDP) to secure measurable financial returns. We'll examine the systemic reasons behind the OCR Paradox and outline a strategic framework for processing complex, unstructured documents like contracts and emails with autonomous precision.
Key Takeaways
• Uncover the "Template Trap" and why rules-based extraction fails to scale in modern, dynamic enterprise environments.
• Understand the structural and strategic reasons why ocr projects fail to deliver roi by exposing the hidden labor costs of manual verification.
• Transition from basic character recognition to Intelligent Document Processing (IDP) to unlock the value of unstructured data like contracts and emails.
• Leverage Agentic AI and the i_Nova platform to move beyond simple data capture toward autonomous workflow execution and downstream system integration.
• Implement a strategic framework that prioritizes contextual intelligence over technical extraction to ensure long-term automation viability.
The OCR Paradox: Why 95% of Document Automation Projects Fail in 2026
The "OCR ROI Gap" is the widening chasm between technical extraction and business utility. While a tool might successfully identify text on a page, it often fails to provide the structured insight required to trigger a measurable financial return. This disconnect is exactly why ocr projects fail to deliver roi so frequently. In 2026, the enterprise landscape is dominated by unstructured data like complex contracts and conversational emails. Legacy OCR systems, built for the rigid forms of the past decade, simply cannot process the fluid nature of modern business communication.
To better understand this concept, watch this helpful video:
Many initiatives suffer from "Pilot Paralysis." A solution performs perfectly in a controlled lab setting using pristine sample documents. However, it collapses in production when faced with real-world noise, skewed scans, or unexpected formatting. This creates "Foundations on Sand," where advanced analytical models are deployed on top of fragmented, low-quality data. Without a stable data foundation, the entire automation architecture remains precarious and fails to scale beyond the initial proof of concept.
Recognition vs. Understanding: The Fundamental Flaw
Legacy OCR is a visual tool; it identifies shapes and translates them into characters. It doesn't understand that a string of numbers represents a "Total Amount Due" or a "Contract Expiration Date." Modern enterprises require more than just vision. They need Intelligent Document Processing (IDP) to bridge the gap between sight and logic. Document Intelligence is the strategic evolution from simple character recognition to autonomous contextual understanding. When layout variations occur, legacy systems break because they lack the cognitive flexibility to adapt to new visual structures.
The ROI Mirage: Why Accuracy Metrics Lie
Marketing teams often tout "99% accuracy," but this is a dangerous metric for a Strategic Architect to rely on. This figure usually refers to character-level accuracy. If an invoice has 1,000 characters and 10 are wrong, you have 99% accuracy. However, if those 10 errors are spread across the "IBAN" and "Total Cost" fields, the entire document is useless for automated processing. A 1% error rate at the character level can necessitate a 100% manual review rate in production. This hidden labor cost is the primary reason why ocr projects fail to deliver roi. Field-level precision is the only metric that correlates with actual P&L impact.
Structural Failures: The Anatomy of a Collapsed OCR Initiative
Structural collapse is rarely the result of a single error. It is the cumulative effect of architectural rigidity. Many enterprises treat document extraction as a standalone task rather than a core data pipeline. This isolation is a primary reason why ocr projects fail to deliver roi when they transition from pilot to production. According to Gartner (2025), 85% of AI project failures stem from poor data quality. In the context of OCR, this quality issue is exacerbated by systems that cannot communicate with the broader enterprise ecosystem.
Bolting legacy OCR onto modern ERP or CRM systems creates significant friction. Extracted text often sits in "dark data" silos, disconnected from downstream workflows. If your data doesn't flow directly into your financial systems, you haven't automated anything; you've just moved the bottleneck. This friction causes scalability walls where adding a new document type requires a linear increase in human oversight and maintenance costs.
The Fragility of Rules-Based Extraction
Rules-based systems rely on static coordinates to find data. If a vendor moves a logo or shifts a line item table by three millimeters, the system fails. Managing thousands of these vendor-specific templates creates an unsustainable maintenance burden. It turns your highly skilled engineers into digital janitors. This is why forward-thinking firms are moving toward Agentic AI Engineering Services. Instead of following rigid rules, agentic systems use reasoning to locate and validate information regardless of the visual layout.
Operationalization and MLOps Gaps
Legacy pipelines lack observability. You can't fix what you can't see. Basic OCR projects often ignore version control and monitoring for model drift. This means accuracy degrades silently as document types evolve. To build a resilient system, you must implement rigorous MLOps Pipelines: The Definitive Guide. This ensures your automation remains stable even as document volumes grow and data patterns shift. If you're unsure where your current infrastructure stands, a targeted AI Strategy & Consulting session can reveal these hidden structural gaps before they erode your returns.
The transition from a fragile experiment to a robust enterprise asset requires a shift in philosophy. You must move away from "fixing" OCR and toward building autonomous data intelligence. This involves integrating extraction directly into your cloud-native architecture to ensure that every byte of data serves a specific business outcome.
The Manual Verification Trap: Calculating the True Cost of Ownership
The most significant reason why ocr projects fail to deliver roi is the systemic underestimation of the "Human-in-the-Loop" requirement. While marketing materials often promise total automation, the reality is frequently a team of employees manually correcting extraction errors. Research from 2026 indicates that correcting a single manual data entry error costs between $15 and $25. When an OCR engine misidentifies fields across thousands of documents, these costs don't just add up; they explode. This hidden labor erodes the very margins the technology was intended to protect.
High-value employees, such as senior accountants or legal analysts, often find their flow interrupted by the need to "babysit" the software. This context-switch tax is expensive. Every time a professional stops a complex task to re-type a vendor name that the OCR missed, you lose the momentum of high-value creative work. The opportunity cost is staggering. Your team isn't just fixing data; they're failing to perform the strategic analysis that drives company growth. Additionally, maintaining custom "cleaning" scripts to post-process messy OCR output adds layers of technical debt. These scripts require constant updates to handle new edge cases, creating a long-term maintenance burden that can rival the cost of the original software license.
A Framework for OCR ROI Calculation
To calculate your true cost per document, you must look beyond the initial license fee. Use this logical framework to assess performance:
Total Cost of Ownership
(Software License + Infrastructure) + (Manual Review Hours x Hourly Rate) + (Error Correction Costs).
Realized Automation Rate
This is the percentage of documents that pass through the system without any human intervention.
The Gap
If your "Theoretical Extraction Rate" is 95% but your Realized Automation Rate is only 20%, your project is failing.
You must also factor in error-driven business mistakes, such as duplicate payments or missed early-payment discounts. These financial leaks are direct consequences of a flawed extraction strategy.
The Psychological Impact of 'Broken' Automation
Unreliable automation creates profound organizational friction. When employees feel they are serving the technology rather than being empowered by it, burnout follows. This frustration leads to deep-seated resistance against future initiatives. If the current tool doesn't work, staff will likely meet the next implementation with skepticism. This is why why ocr projects fail to deliver roi is often a cultural issue as much as a technical one. Professional Enterprise AI Strategy Consulting is vital for navigating this transition. It helps leaders move toward agentic systems that actually remove the burden of repetitive tasks, restoring employee faith in the digital transformation roadmap.
Transitioning to IDP: From Text Extraction to Workflow Execution
OCR is a legacy lens. It views documents as static images to be transcribed. Intelligent Document Processing (IDP) represents a fundamental shift from simple character recognition to autonomous contextual reasoning. This cloud-native, AI-first evolution doesn't just ask "What does this document say?" It asks "What does this mean for our business?" This distinction is critical. If your system merely extracts text without understanding its purpose, you still have a manual processing bottleneck. This is precisely why ocr projects fail to deliver roi when they lack a bridge to actual business logic.
Modern IDP leverages Large Language Models (LLMs) to achieve zero-shot extraction. Unlike legacy systems that require thousands of brittle templates, LLMs understand the semantic intent of a document regardless of its layout. They can identify a "Force Majeure" clause in a contract or a "Disputed Line Item" in an email with human-like precision but at machine speed. By integrating Agentic AI, your organization can move beyond data capture toward autonomous workflow execution, where documents trigger their own downstream actions in your ERP or CRM.
The 5 Pillars of a Successful IDP Strategy
Building a resilient document intelligence ecosystem requires a structured approach. Follow these five pillars to ensure long-term viability:
Step 1: Data Engineering.
Clean your "Dark Data" foundation. High-quality Data Engineering & AI Services ensure that the information fed into your models is structured and accessible.
Step 2: Contextual Understanding.
Deploy LLMs to interpret documents without relying on coordinates. This eliminates the maintenance burden of rules-based templates.
Step 3: Agentic Orchestration.
Use AI agents to trigger business logic. For example, a system can auto-approve a low-risk invoice if it matches a pre-authorized purchase order.
Step 4: Continuous Learning.
Implement feedback loops where human-on-the-loop corrections are used to fine-tune model performance over time.
Step 5: Governance and Compliance.
Ensure every automated step aligns with SOC2 and GDPR requirements to maintain enterprise security.
Agentic AI: The Final Piece of the ROI Puzzle
The true financial breakthrough occurs when you shift from "human-in-the-loop" to "human-on-the-loop." In legacy OCR, humans are required to fix every minor extraction error. In an agentic framework, AI agents interact directly with your legacy software to complete tasks autonomously. Humans only intervene for high-level strategic exceptions. This transition allows your team to focus on high-value creative work rather than repetitive data entry. To understand how this works at scale, read our What Is Agentic AI? The Executive Guide. If you're ready to modernize your back office, our Agentic AI Engineering Services can help you build a frictionless, automated future.
Engineering ROI with i_Nova and IntellifyAi's Strategic Framework
Understanding why ocr projects fail to deliver roi is the first step toward enterprise modernization. The second step is deploying a framework that prioritizes business utility over technical extraction. At IntellifyAi, we act as your Strategic Architect. we bridge the gap between abstract technological potential and the practical needs of a growing company. Our approach replaces the fragile, template-heavy methods of the past with a robust, agentic architecture designed for long-term financial performance.
We mitigate deployment risk through a rigorous Proof of Value (PoV) methodology. Rather than asking you to commit to a full-scale implementation based on lab results, we demonstrate measurable P&L impact in a controlled environment. This ensures that every dollar invested in your document intelligence ecosystem correlates directly with a reduction in manual labor or an increase in process velocity. We don't just build software; we engineer sustainable competitive advantages.
The i_Nova Advantage: Intelligence at Scale
The core of our technical solution is the i_Nova platform. This multimodal AI engine is specifically designed to navigate the complexities of unstructured data that legacy tools ignore. While basic OCR struggles with varying formats, i_Nova processes diverse document types, from handwritten notes to complex legal contracts, with autonomous precision. It moves beyond raw data extraction to provide actionable intelligence that your business can use immediately. By visiting our IntellifyAi Products page, you can see how this engine integrates into your existing cloud-native environment to unlock the value of your dark data silos.
Consulting and Managed Services for Long-Term Viability
ROI decay is a common threat in document automation. As document layouts evolve and business requirements shift, unmanaged models lose their accuracy. We prevent this through a comprehensive suite of AI Strategy & Consulting services that focus on continuous optimization and MLOps. We treat your AI implementation as a living business pillar rather than a temporary fix. Our team manages model performance and monitors for drift, ensuring that your automation remains resilient in a dynamic market.
True digital transformation requires more than just a software license. It requires a partner who understands the collaborative relationship between technology and human workers. We frame our tools as a means to unlock human potential, allowing your staff to focus on high-value creative work while our agents handle the repetitive tasks. If you are ready to move beyond the limitations of legacy systems, Consult with our AI Strategy Team today to build a frictionless, automated future for your enterprise.
Reclaiming the Value of Document Intelligence
The transition from legacy character recognition to autonomous document intelligence is no longer optional for the modern enterprise. We have explored the structural gaps and the manual verification trap that explain why ocr projects fail to deliver roi in today's high-velocity market. By shifting your focus from what characters are on the page to what business logic this data triggers, you eliminate the friction of brittle templates and hidden labor costs. True digital transformation requires a foundation built on contextual understanding rather than static rules.
IntellifyAi stands ready as your Strategic Architect. We specialize in Agentic AI and Cloud-Native modernization, ensuring your automation initiatives are durable and scalable. Our flagship i_Nova platform is specifically engineered to master unstructured data, turning complex documents into actionable insights. Through our strategic AI consulting, we help global enterprises bridge the gap between abstract technology and measurable financial performance. Stop settling for brittle OCR. Partner with IntellifyAi for Agentic Document Intelligence. Your path to a frictionless, automated future starts with a single strategic pivot.
Frequently Asked Questions
Why does OCR accuracy drop when I scale the number of documents?
Scaling exposes your system to increased document variety and layout shifts that legacy tools cannot handle. Traditional OCR relies on rigid templates; as you add more vendors or document types, the probability of a document deviating from a saved template increases. This leads to "template drift," where the system fails to recognize fields it previously captured. Without a cognitive layer to understand document structure, accuracy inevitably degrades as volume and complexity grow.
What is the difference between OCR and Intelligent Document Processing (IDP)?
OCR is a visual tool that translates images into text, while IDP is an AI-driven framework that understands the context and intent of that text. OCR sees characters; IDP understands business logic. IDP uses machine learning and natural language processing to classify, validate, and extract data from unstructured sources. This contextual intelligence is the primary reason why ocr projects fail to deliver roi when they lack modern IDP capabilities.
How can Agentic AI help recover a failing OCR project?
Agentic AI moves beyond simple extraction by autonomously executing the next logical steps in a business workflow. Instead of just flagging an error for a human to fix, an AI agent can query an ERP system to resolve discrepancies or cross-reference data across multiple sources. By shifting the burden from manual cleanup to autonomous resolution, Agentic AI bridges the performance gap that traditional OCR leaves behind, securing the financial returns originally promised.
What are the hidden costs of manual document verification?
The most significant hidden costs include high labor rates for "Human-in-the-Loop" tasks and the financial impact of downstream errors. Research indicates that fixing a single manual data entry error can cost between $15 and $25. Beyond direct costs, manual verification causes employee burnout and significant opportunity costs. When highly skilled staff spend 30% to 50% of their time re-typing data, the business loses the value of their strategic expertise.
How much unstructured data can i_Nova process compared to legacy tools?
i_Nova is designed specifically for the complex, unstructured data that legacy tools often cannot process at all. While traditional OCR requires structured forms or semi-structured invoices, i_Nova handles fluid documents such as legal contracts, conversational emails, and multi-page reports. It focuses on actionable intelligence rather than raw text extraction. This allows enterprises to automate the 80% of their data that currently resides in inaccessible, dark silos.
Is it better to build a custom IDP solution or buy a platform like i_Nova?
Buying a mature platform like i_Nova is generally more cost-effective for enterprises looking for rapid deployment and long-term stability. Building a custom solution requires massive investment in data engineering, model training, and continuous MLOps maintenance. A platform approach provides immediate access to advanced multimodal AI while allowing your internal teams to focus on high-value integration and strategy rather than managing the underlying infrastructure and model drift.
How do I calculate the ROI of an IDP project before starting?
Calculate ROI by comparing your current "Cost per Document" against the projected costs of an automated, agentic workflow. You must include the cost of manual review time, error correction fees, and technical debt from legacy systems. A successful project should target a high "Realized Automation Rate" rather than just a theoretical accuracy percentage. This financial clarity is essential to avoid the common pitfalls that explain why ocr projects fail to deliver roi.
What role does data engineering play in document automation success?
Data engineering provides the stable foundation required for any AI-driven extraction. It involves cleaning "dark data," ensuring system interoperability, and building resilient pipelines that feed high-quality information into your models. Without rigorous data engineering, even the most advanced AI will fail due to poor input quality. It is the bridge that connects raw document images to structured, usable business intelligence across your entire enterprise ecosystem.






.svg)
